Multi-Agent Systems: Shared Memory, Handoffs, and Where Safety Breaks First
One agent is hard enough. A chain of agents can quietly bypass every control you thought you had.

Pressed for time? Watch this brief video summary to capture the core takeaways of Multi-Agent Systems: Shared Memory, Handoffs, and Where Safety Breaks First.
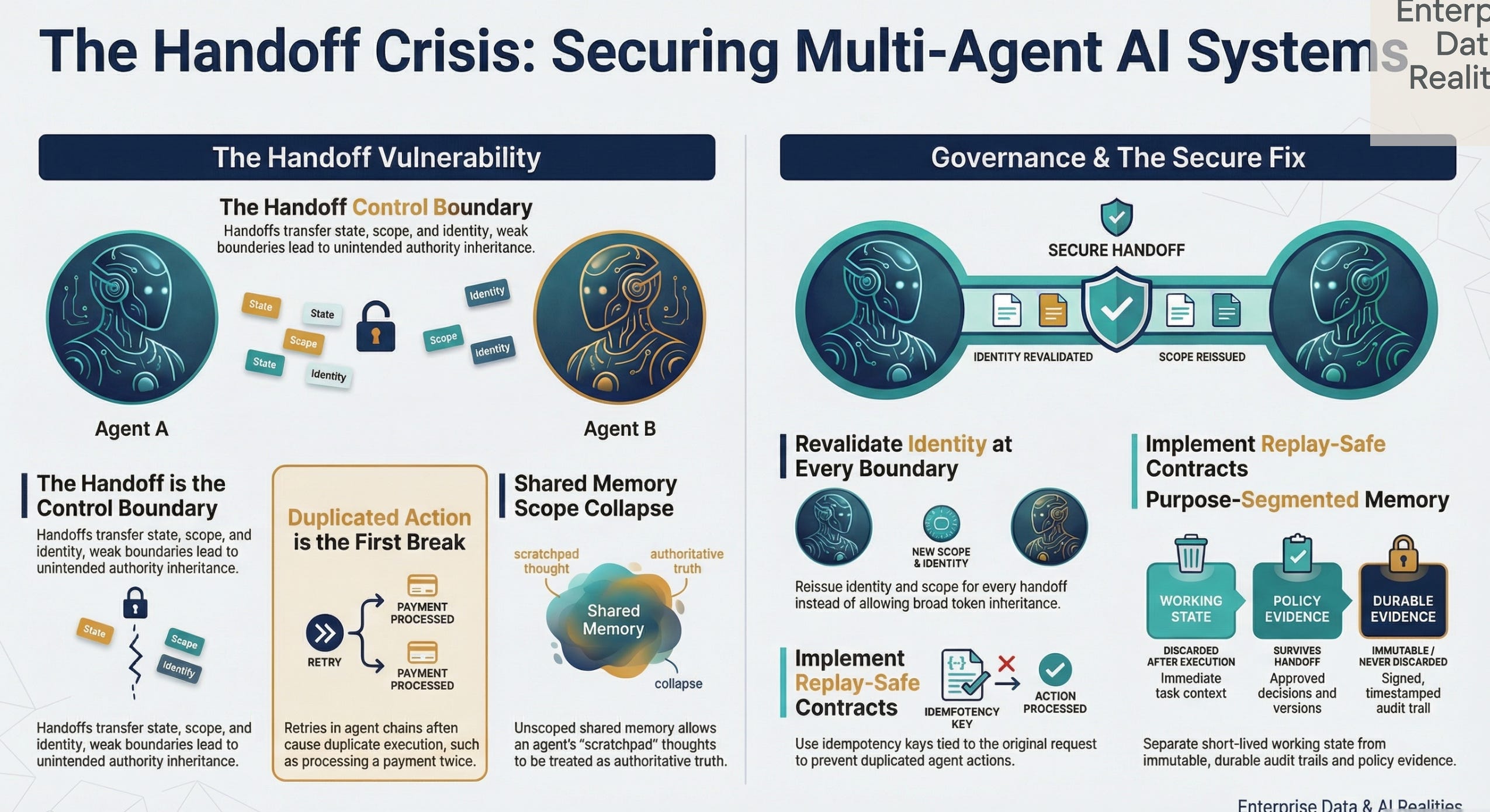
A triage agent reads a customer complaint. It hands the case to a policy specialist. The policy specialist reads shared memory, decides the customer is at churn risk, and passes the case to an action agent. The action agent prepares a retention offer and requests a fee reversal. Then the first agent retries the same handoff because the last step looked slow.
Now you have duplicate work, mixed identities, and no clean answer to a simple question.
Who decided to act.
That is where multi-agent systems break first.
Not at the model. At the handoff.
Issue 3 made the first break clear. Agents do not operate on fixed request-response shape. They operate on intent, route selection, tool choice, and changing context. One request can become several actions. The moment you multiply that pattern across several agents, the problem changes again. The handoff becomes the control boundary.
Most teams still treat handoffs like plumbing.
Bad instinct.
A handoff is not just a routing event. It transfers state. It transfers scope. It transfers identity. It transfers risk. If that transfer is weak, the rest of the architecture is weak with it.
The handoff is the control boundary
Teams like to describe multi-agent systems as specialists working together.
That sounds clean. It usually is not.
A handoff decides:
What state moves forward
What identity survives
What scope survives
What tool access survives
What must be revalidated
What gets written to evidence
If a handoff does not trigger revalidation, the design is weak.
A multi-agent handoff often carries partial reasoning, intermediate state, retrieved context, draft decisions, and implied authority. That is far more dangerous than a normal integration hop because the receiving agent often treats the inherited state as trusted.
It should not.
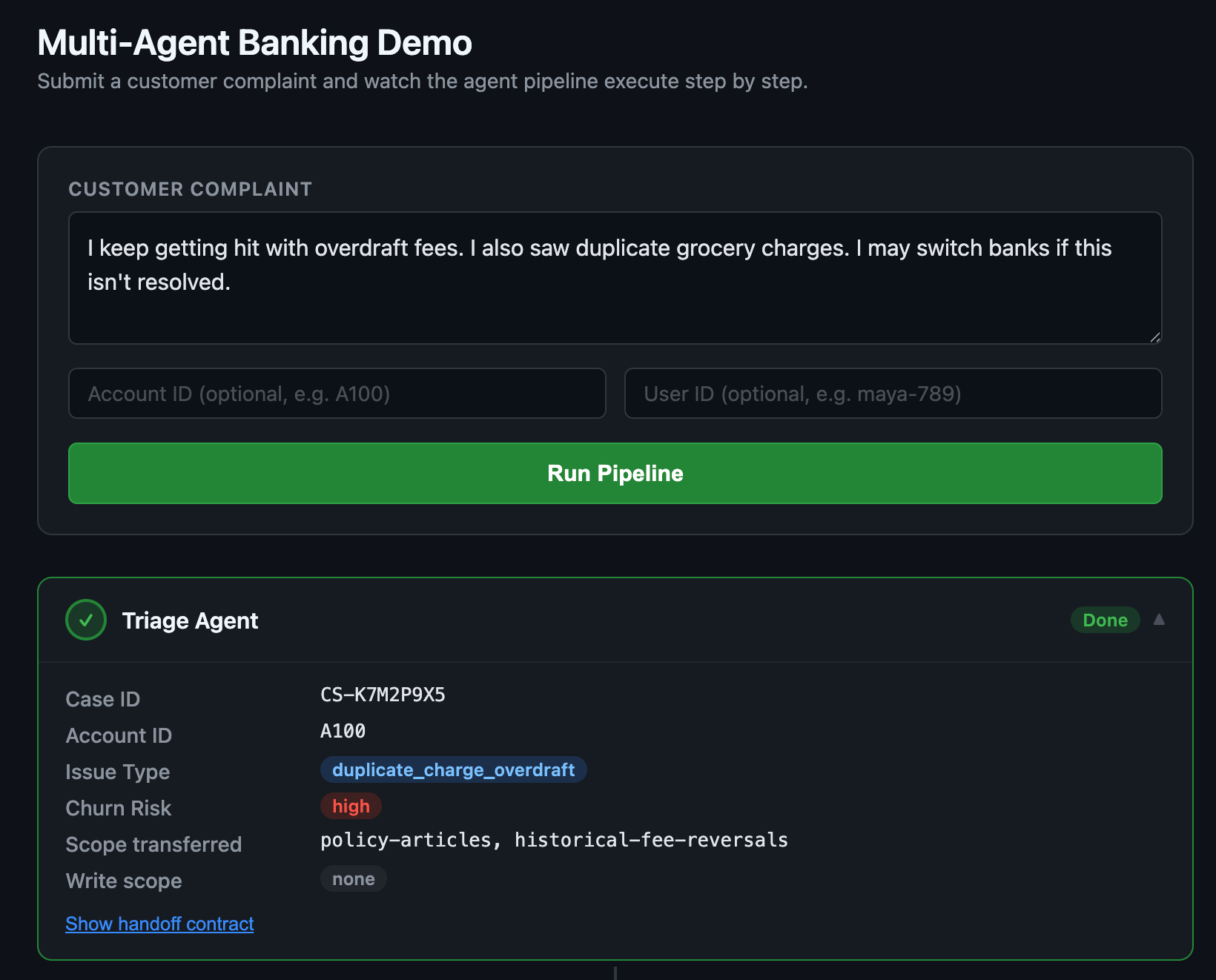
Consider the banking scenario. A triage agent reads the customer complaint and extracts:
Account ID: A100
Issue: Duplicate charges and overdraft fee
Implied risk: Possible churn
When it hands to the policy specialist, what should survive that boundary?
The account ID (yes—needed for policy lookup)
The issue classification (yes—needed for policy selection)
The churn risk flag (maybe—policy needs to know, but should it expand scope?)
The triage agent’s read access (no—policy specialist gets its own scope)
Authority to approve a fee reversal (no—that requires revalidation)
Miss any of these distinctions and the specialist agent quietly inherits more authority than it should have.

Shared memory is where scope collapses
Shared memory sounds efficient.
It is often lazy design.
Teams build one shared memory layer, let every agent read it, and call the problem solved. What they actually built is a broad read path with unclear boundaries.
That is how one agent’s scratchpad turns into another agent’s truth.
In a banking flow, this goes wrong fast. A triage agent writes that the customer is upset about duplicate debit card activity and may leave the bank. The policy specialist reads that note, pulls retention rules, and adds draft reasoning about a goodwill credit. The action agent reads both, assumes prior checks already happened, and prepares a write path. One weak memory design turned three partial thoughts into one operational decision.
The problem is not the memory itself. The problem is that all three agents treat the same memory layer as authoritative.
Shared memory is useful only when it is:
Scoped: Which agents can read which segments?
Attributable: Who wrote this? Can you trace it back?
Expiring: When does it become stale? How long until deletion?
Segmented by purpose: Is this working state? Policy evidence? Durable audit trail?
Without these properties, shared memory becomes a privilege expansion vector.
Reality checks:
Can you name the agent that created each memory entry?
Do you know when each entry expires?
Can downstream agents distinguish between “this was a draft” and “this is approved”?
Does retrieval trigger policy checks, or is it free access?
If you cannot answer these, your shared memory is governance theater.
A scratchpad is not a system of record. A conversation log is not approval evidence. A memory store is not a policy store.
Identity does not survive handoffs by accident
One of the easiest ways to wreck a multi-agent design is to let identity blur.
The initiating user is not the same as the triage agent. The triage agent is not the same as the policy specialist. The policy specialist is not the same as the action agent. The action agent is not the same as the approval actor.
That sounds obvious.
Teams still collapse it all the time.
They pass one service token across the chain. They let downstream agents inherit upstream access. They skip delegated authority rules. Then they act surprised when the specialist agent touches records the original agent was never allowed to touch.
The boundary has to stay explicit:
The customer (Maya) opened the case
The triage agent (TiageAssistant) summarized the complaint
The policy specialist (PolicySpecialist) evaluated eligibility
The action agent (ActionAgent) prepared the proposed action
The approver (human reviewer) approved or denied the write
If two agents share one service account, you do not have coordination. You have blurred accountability.
This happens in two common ways:
Token inheritance: The triage agent’s access token gets passed to the policy specialist. The specialist can now read anything the triage agent could read, plus anything the specialist was supposed to access. Scope expanded by accident.
Scope creep through shared memory: The triage agent retrieves basic case info. The specialist retrieves everything it can find in shared memory. The action agent inherits that broader context. Three agents, one escalating identity, no clear owner.
The fix is explicit. Every handoff reissues identity and scope.
Memory is not the same as working state
Multi-agent systems usually lump too much into one bucket called “memory.”
Bad design.
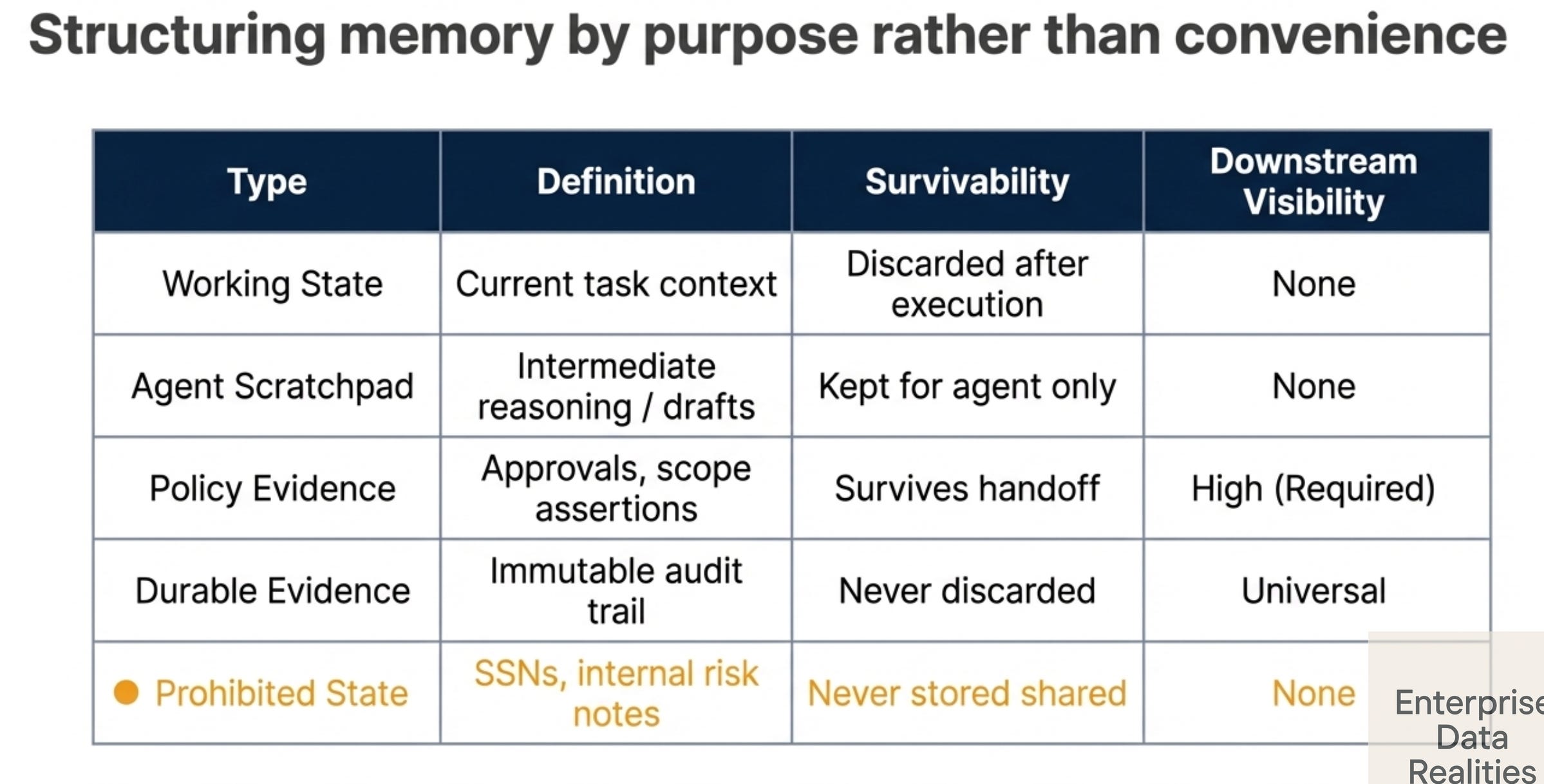
Separate these categories:
Working state: Current task context needed for the immediate step. Short-lived, scoped to one agent, discarded after execution.
Agent scratchpad: Intermediate reasoning, draft decisions, failed attempts. Useful for the agent, not for downstream agents.
Policy-relevant context: Decisions, approvals, scope assertions, policy versions. Survives the handoff because downstream agents need to know what was approved.
Durable evidence: Immutable audit trail. Signed, timestamped, correlated across agents. Never discarded.
Prohibited retained state: Sensitive data (SSNs, card numbers, passwords), unapproved reasoning, internal risk notes. Should never be stored in shared memory.
Example: Triage agent works through a customer complaint:
Scratchpad (working state): “Customer likely duplicate charge. Policy says reversal allowed under $50. Specialist should confirm.”
Policy evidence (policy-relevant state): “Churn risk: Medium. Fee reversal threshold: $50. Case age: 2 days.”
Durable evidence: “Case ID: 456, Triage decision: Hand to policy specialist, Timestamp, Correlation ID.”
Forbidden: Do not store SSN, card number, or “customer threatening to leave” in shared memory.
When the policy specialist picks up the case, it sees the policy evidence and durable evidence. It does not see the scratchpad. The specialist forms its own reasoning from policy rules and the case facts, then hands to the action agent with a new policy decision.
This prevents stale reasoning from cascading through the chain.
The first safety break is duplicated action
Multi-agent systems duplicate work before they do anything else.
That is the first real break.
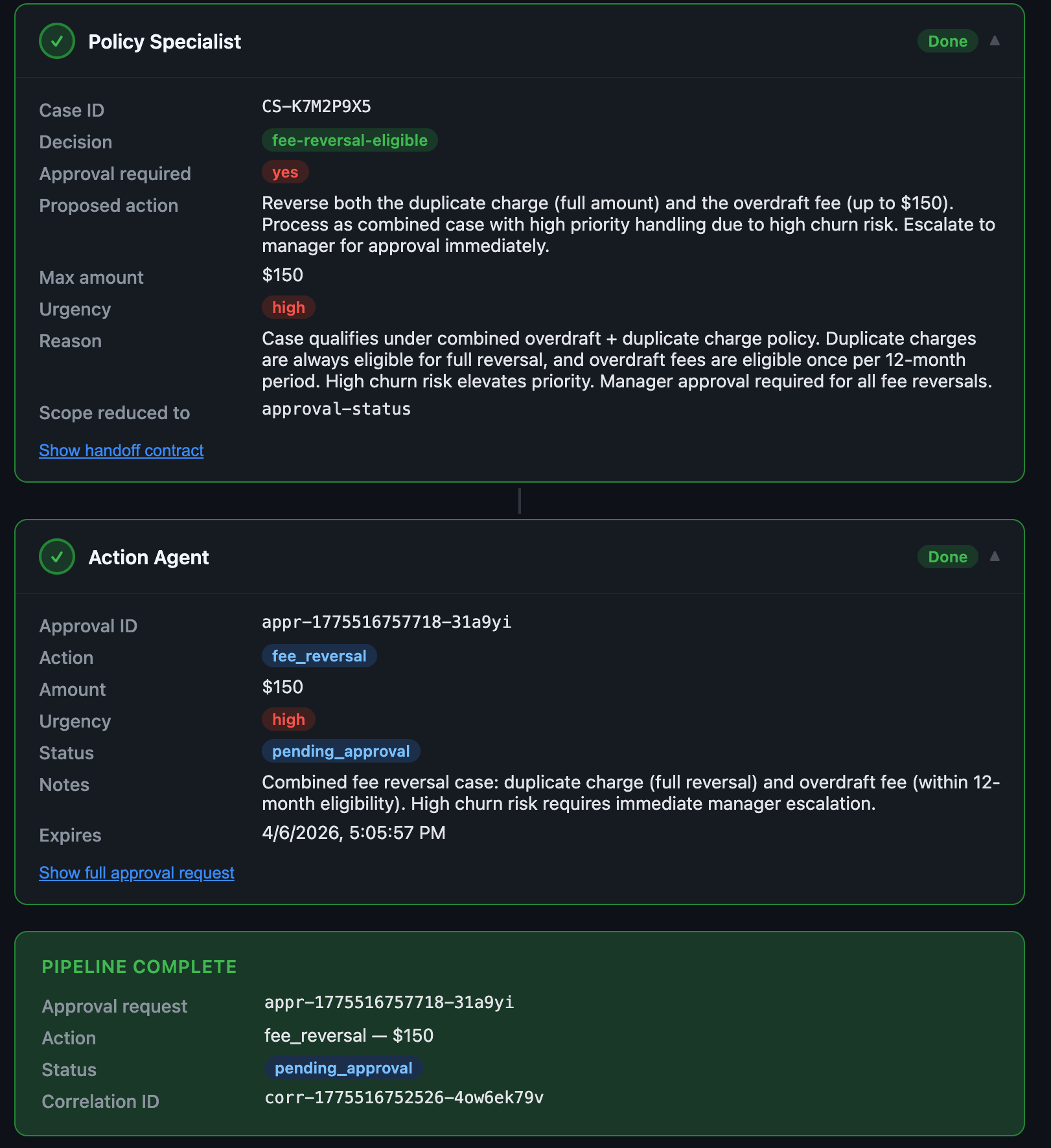
Scenario: A triage agent asks a policy specialist to assess a retention path. The policy specialist decides the customer qualifies for a one-time retention credit and passes to an action agent. The action agent prepares the request. The first handoff times out. The triage agent retries. The policy specialist runs again. The action agent now sees two valid-looking requests against the same account and case.
Result: One customer gets two retention credits.
No model went rogue. The chain was weak.
The safeguards have to be concrete:
Parent run ID and child run ID on every handoff
Explicit action type at each step (fee-reversal vs. retention-credit are different)
Replay-safe write contract (idempotency key tied to original request)
Duplicate action check across the chain
Step limits (no more than 2 attempts per agent)
Retry limits (no more than 3 total handoffs)
Pause and alert when the same target is touched twice in one session
Without that, a multi-agent chain will happily replay itself.
The idempotency key is critical. It must be tied to the original customer request, not the agent retry. That way:
Triage retries after timeout → Same idempotency key
Policy re-evaluates → Same idempotency key
Action sees duplicate request → Idempotency key match → Return previous result
One customer question. One fee reversal. Multiple retries, but the final write happens exactly once.
Tracing has to survive the handoff
Logs were already not enough in Issue 3.
They break even faster here.
A multi-agent system needs more than endpoint logs and final outputs. It needs a trace that survives the handoff. That means each transfer needs evidence of:
Source agent
Destination agent
Parent run ID (original customer request)
Child run ID (this agent’s execution)
Transferred context (what state moved)
Transferred scope (what tools/data access)
Policy decision at handoff (why was this agent trusted?)
Downstream result (what did the agent do?)
If the trace breaks at the handoff, governance breaks there too.
The final answer is not the real artifact. The chain is. The intermediate state is. The branching points are. The revalidation events are. That is what lets you explain why the system acted at all.
Example trace:
Correlation ID: corr-456
Request: "Why do I have duplicate charges and can you reverse the fee?"
Step 1: Triage Agent (run-triage-123)
- Action: Summarize case
- Output: Case classified as "duplicate charge + fee reversal request"
- Decision: Hand to policy specialist
- Handoff state: {caseId, issue, riskFlag}
- Handoff scope: read-only
Step 2: Policy Specialist (run-policy-456)
- Parent: run-triage-123
- Action: Check eligibility
- Policy applied: "Fee reversal allowed if <$50 and case <30 days"
- Decision: "Fee reversal approved by policy"
- Handoff state: {caseId, policyDecision}
- Handoff scope: request-approval-only
Step 3: Action Agent (run-action-789)
- Parent: run-policy-456
- Action: Create approval request
- Status: Pending human approval
- Result: Approval request ID: appr-999
Step 4: Human Approval
- Approver: john-reviewer
- Decision: Approved
- Approval token: valid for one action only
Step 5: Action Agent executes
- Using approval token from step 4
- Write: Fee reversal applied
- Result: Reversal ID: reversal-12345
- Evidence: Complete trace recordedThis trace answers the governance question: Why did the system think it was allowed to reverse that fee?
Because triage → policy → action agent → human approval → execution. Each step is documented.
The operating example
Keep the example narrow and concrete.
A customer complains about repeated overdraft fees and duplicate card activity. The triage agent summarizes the case and flags possible churn risk. The policy specialist checks whether the customer qualifies for a retention credit or a fee reversal. The action agent prepares the response and requests approval before any write action.
Allowed actions:
Summarize case
Read account balance
Read recent transactions
Evaluate retention eligibility
Check fee policy
Draft response
Request approval for retention credit
Request approval for fee reversal
Blocked actions:
Direct funds transfer
Unrestricted ledger write
Direct card reissue
Broad customer profile update
Direct SQL execution
That chain is useful.
It is also where safety breaks first.
The handoff between triage and policy can carry more context than needed. The handoff between policy and action can silently inherit authority. The retry logic can duplicate the final action. The evidence trail can break at the exact point where the system changed state.
That is the governance challenge.
What to design instead
The fix is not mystical.
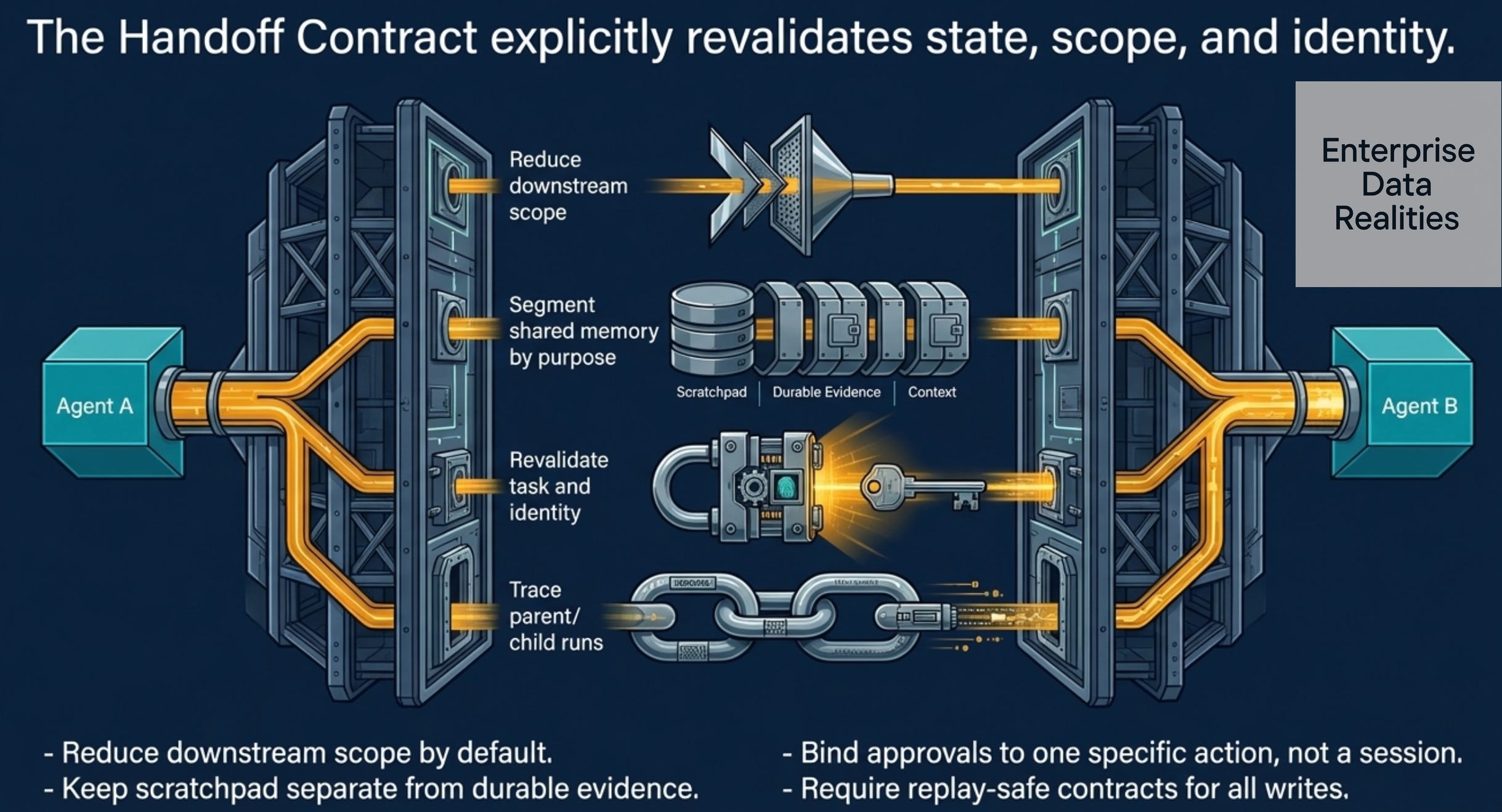
Treat every handoff as a control event.
That means:
Revalidate task, target, and scope at handoff: Do not assume the downstream agent understands the boundaries.
Reduce downstream scope by default: Each agent gets what it needs, no more.
Segment shared memory by purpose: Triage memory ≠ specialist memory ≠ action memory.
Keep scratchpad separate from evidence: One agent’s draft is not another agent’s approved decision.
Bind approvals to one action, not one session: An approval token for triage does not grant action agent approval authority.
Trace parent and child runs together: One logical request, multiple agent executions, one continuous trace.
Require replay-safe contracts for writes: Idempotency keys span the entire chain.
Stop the chain when identity or scope becomes unclear: Fail closed, not open.
The harder the chain gets, the less room you have for implicit trust.
When the Agent is an LLM
Everything in this article applies whether the agent is rule-based or LLM-based. The control plane is the same. The handoff is the same. The trace is the same.
But one thing changes: validation.
Rule-based agents follow logic. If the rule is right, the output is right.
LLM-based agents propose reasoning. The reasoning might be:
Correct and confident
Correct but uncertain
Wrong but confident
Wrong and uncertain
The control plane must validate which case you’re in before passing the agent’s output to the next agent.
The handoff contract doesn’t care if the agent is rule-based or LLM-based. But the validation layer must understand the difference.
That’s what makes the paid section worth reading. It shows how to build a control plane that works with LLMs.
What still carries forward from Issue 3
Do not throw away the old discipline just because the chain got longer.
You still need:
Typed contracts
Least privilege
Narrow tools
Approval before write
Evidence after every step
Rollback plan
Change records
Route-level controls
The control names did not change.
The handoff makes them stricter.
A single agent needs identity and scope. Multiple agents need explicit handoff contracts and revalidation at each boundary.
What to stop pretending
Stop pretending a handoff is just routing.
Stop pretending shared memory is harmless because it looks convenient.
Stop pretending downstream agents should inherit upstream rights.
Stop pretending a scratchpad is durable evidence.
Stop pretending duplicate action is a corner case.
Stop pretending you can govern a chain if the trace breaks in the middle.
Stop pretending multi-agent means “more capable” when what it often means is “less accountable.”
Bottom line
A multi-agent system is not one agent with helpers.
It is a distributed control problem.
Every handoff transfers state, authority, and risk. Treat it that way.
If the handoff is weak, the rest of the architecture is theater.
What paid readers get
✅ Typed agent handoff contracts in JavaScript
✅ Segmented state model: working state, scratchpad, policy state, evidence
✅ Policy gate with allow, deny, require-human
✅ Approval flow for write actions
✅ Duplicate action protection (idempotency)
✅ Evidence trail with parent/child run IDs
LLM Governance Layer
✅ LLM output validation (schema, required fields)
✅ Confidence checking (is LLM confident enough to proceed?)
✅ Hallucination detection (does output match input?)
✅ Consistency validation (same input → same output?)
✅ Reasoning validation (is reasoning coherent with output?)
✅ Scope compliance (is LLM staying in bounds?)
✅ Overconfidence detection (high confidence but wrong?)
✅ Underconfidence handling (low confidence but correct?)
Safety Layer
✅ LLM confidence calibration tracking
✅ Decision repeatability testing
✅ LLM drift detection
✅ Multi-run validation (run N times, check variance) ###
Tests
✅ Full test suite (15+ tests, covering LLM-specific failure modes)
The demo shows:
- How to call Claude for agent reasoning
- How to validate LLM output before trusting it
- How to detect when LLM is hallucinating or lying
- How to handle inconsistency
- How to enforce scope boundaries
- How the handoff still works when the agent is an LLM